A Real-time Recipe for Rails and Ember using Pusher
The ability to update in real-time is a requirement for web applications today. We should expect the users to do as little as possible, and requiring a refresh to pull down the latest app state is one extra action.
Nevertheless, designing front- and back-end systems with this constraint in mind can be challenging. Implemented poorly, you can end up with soup of events, channels, and callbacks. This blog post outlines the basic strategy I use to push state changes in the database to the front-end.
The Stack
For this blog post, I’ll be using code snippets that assume the following frameworks:
- Rails 5, although this should work with Rails 3+
- Ember 2.8.0 with Ember Data, although this will also work in Ember 1.x
- Pusher (3.1 of their JS library, and 1.1 of their Ruby gem)
These are my basic building blocks for a real-time stack, and they are primarily chosen for their convention over configuration approach.
Pusher is my service of choice for dealing with WebSocket communication. I have used home-spun socket.io services in the past, but never found the graceful fallback mechanisms to work all that well. Granted, those were pre-1.0 days.
The design laid out in this post is designed to minimize drift. Implemented hastily, introducing real-time updates into an app opens up race conditions and other ways the client-side state may differ from server-side state. We want to make sure that our client-side state doesn’t change should a user manually refresh.
The Data Flow
I like to think of my application as a big feedback loop, for the purposes of real-time events. Here’s how the data flows through our application.
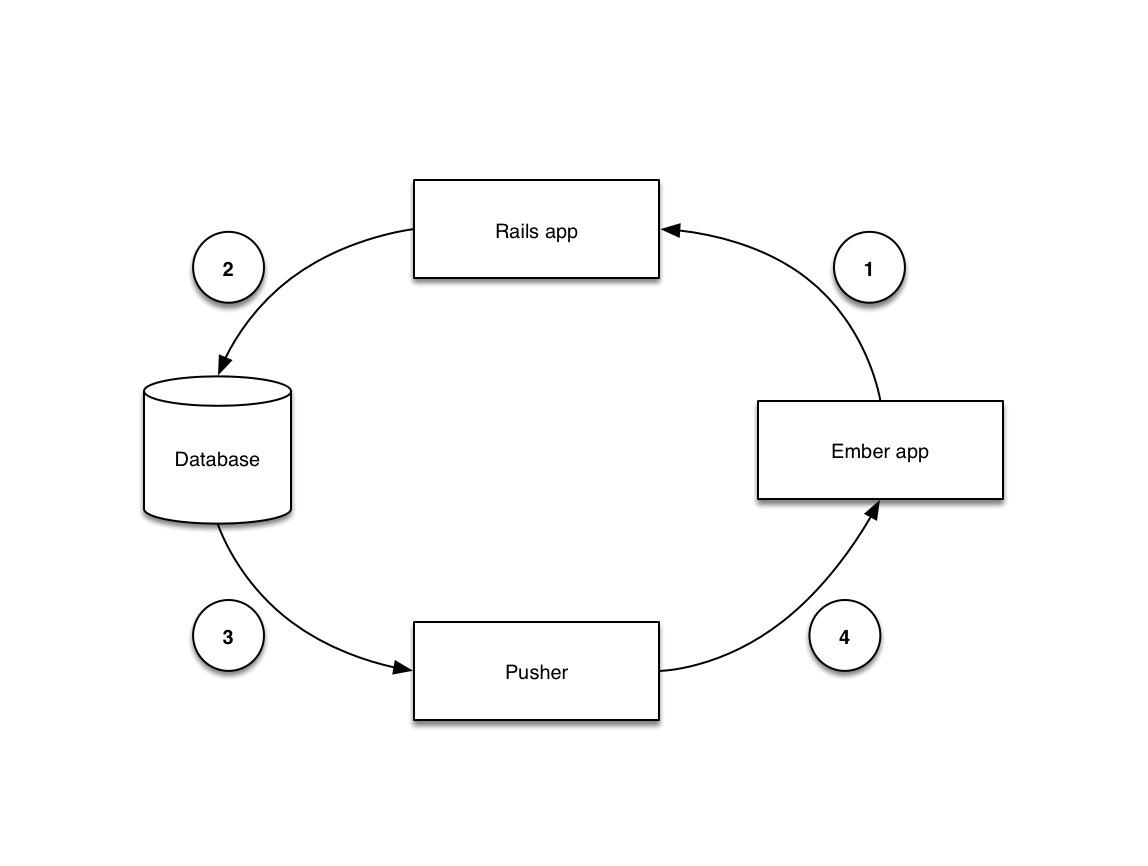
The data flows as follows:
- As the user interacts with the application, data is saved to the Rails application using Ember Data. Ember Data uses json:api as its JSON formatting spec, and the Rails app uses JSONAPI::Resources to expose its endpoints.
- The Rails application receives the data and might do some validation before persisting the data to the database.
- When the data has been successfully persisted to the database, we push that state to Pusher. The Rails app is the one coordinating this.
- Pusher receives the data and pushes it to all interested clients.
As the user uses the app, they may trigger this cycle many times within a session. As background work completes or their colleagues’ use the app, each client stays up to date.
Not pictured here is how the Ember app will fetch data from the Rails app the initial load of the app, but that should be pretty simple given how well Ember Data works with json:api.
Let’s look at the components required to make this happen.
Server-side Implementation
First, let’s dive into how our Rails app will receive data and send it out through Pusher. We don’t care how the Rails app receives data necessarily, but only what to do when data has changed.
To wire things up, we’ll need the following:
- A few models that we want to enable real-time updates for
- An
ActiveSupport::Concernfor sprinkling in some real-time logic - A Sidekiq worker for safely enqueuing messages to be sent to Pusher
A few notes on dependencies:
- I’m using v0.8.0.beta2 of the JSONAPI::Resources gem
- I’m using Sidekiq v4.1.4.
First, let’s take a look at what will be required to make one of our models get the real-time sprinkling:
# app/models/comment.rb
class Comment < ActiveRecord::Base
include PublishesUpdatesToPusher
end
Nice and simple. Let’s take a look at the definition for PublishesUpdatesToPusher:
# app/models/concerns/publishes_updates_to_pusher.rb
require 'active_support/concern'
module PublishesUpdatesToPusher
extend ActiveSupport::Concern
included do
after_commit :notify_via_pusher, on: [:create, :update]
def notify_via_pusher
if Sidekiq.server?
PusherUpdateWorker.new.perform(self.class.name, id)
else
PusherUpdateWorker.perform_async(self.class.name, id)
end
end
end
end
The PublishesUpdatesToPusher concern defines a single method to tee up data to be sent to Pusher.
We use the after_commit callback to make this method be called automatically whenever a record is created or updated. It’s important to use after_commit and not after_save or after_create to ensure the data has been persisted to the database. Without after_commit, we would introduce a race condition where our real-time updates could be sent with stale data.
There’s another flourish here, which is the if Sidekiq.server? check. If we’re already within the context of a Sidekiq job (i.e. we’re doing some background processing), this check allows us to not requeue the job to send it out in real-time and instead do it inline. Because we are within the context of a Sidekiq job, i.e. Sidekiq.server? == true, we know we are outside the critical path of a request. If Pusher is down or slow, we won’t be adversely affecting performance of our own clients.
With that being done, let’s take a look at the definition for PusherUpdateWorker:
# app/workers/pusher_update_worker.rb
class PusherUpdateWorker
include Sidekiq::Worker
def perform(klass, id)
Pusher.encrypted = true
pusher = Pusher::Client.from_env
obj = Object.const_get(klass).find(id)
channel_id = "User-#{obj.user_id}"
resource_klass = Object.const_get("#{klass}Resource")
serialized = JSONAPI::ResourceSerializer.new(resource_klass, {
always_include_to_one_linkage_data: true,
always_include_to_many_linkage_data: true
}).serialize_to_hash(resource_klass.new(obj, nil))
pusher.trigger(channel_id, "objectUpdated", serialized)
end
end
A bit more to unpack here. Let’s break it down line-by-line.
First, we initialize our Pusher client with the lines:
Pusher.encrypted = true
pusher = Pusher::Client.from_envFor this to succeed, our environment or .env must have defined PUSHER_URL.
Next we pull the object in question out of the database with:
obj = Object.const_get(klass).find(id)Then, we initialize our channel_id. The channel_id should be the “top-most” resource on the object graph. Usually this is a User, a Team, or an Organization. This is the only channel a client application will listen to. This assumes that each object implements a #user_id method.
channel_id = "User-#{obj.user_id}"For security purposes, although not covered in this post, you will likely want this channel to be a private Pusher channel.
Next we get to the JSONAPI::Resources specific code section:
resource_klass = Object.const_get("#{klass}Resource")The resource_klass is the associated JSONAPI::Resource for our model. Using Comment as an example, this would be CommentResource. In JSONAPI::Resources, each model gets an associate resource to define which attributes can be readable and writeable under which contexts.
Next, we serialize our data using the same serializers that our controllers use. By doing this, we allow clients to use the same codepaths for loading this data, regardless of if the data is pushed over a WebSocket or retrieve in a normal HTTP request.
Here’s how that is done with JSONAPI::Resources:
serialized = JSONAPI::ResourceSerializer.new(resource_klass, {
always_include_to_one_linkage_data: true,
always_include_to_many_linkage_data: true
}).serialize_to_hash(resource_klass.new(obj, nil))The :always_include_to_one_linkage_data and :always_include_to_many_linkage_data keys in the options hash make sure that we also send any relationship updates to clients. This ensures that we don’t run into the situation where the individual objects have up-to-date data but their relationships are stale.
Finally, we send our serialized data across the appropriate Pusher channel with the event name of "objectUpdated":
pusher.trigger(channel_id, "objectUpdated", serialized)Now we’ve got a stew going.
Client-side Implementation
So the server is pushing data out on each change, now it’s up to the client to listen on those changes and do something with that data.
Because we’re using Ember Data, we only have one place to push data! Because of Ember’s computed properties, once our central store is updated, everything that depends on that data gets updated as well.
First thing’s first, we need to include the Pusher library in our application. There are a few ways to do this, but I just drop the following snippet in my index.html within the <body> after before the Ember vendor.js and app packages:
<script src="https://js.pusher.com/3.1/pusher.min.js"></script>
Next, we’ll define a Pusher service to contain all of our Pusher logic.
// app/services/pusher.js
import Ember from 'ember';
import ENV from 'my-app-name/config/environment';
/* global Pusher */
const { computed, run } = Ember;
export default Ember.Service.extend({
store: Ember.inject.service(),
listenToUser(user) {
if (this.get('hasSubscribedToUser')) {
return;
}
this.subscribe(`User-${user.get('id')}`, "objectUpdated", (data) => {
run.scheduleOnce('afterRender', this, this._pushPayload, data);
});
this.set('hasSubscribedToUser', true);
},
subscribe(channelName, event, callback) {
const channel = this.get('_client').subscribe(channelName);
channel.bind(event, callback);
},
_pushPayload(data) {
this.get('store').pushPayload(data);
},
_client: computed(function() {
Pusher.logToConsole = ENV.environment !== "production";
return new Pusher(ENV.pusher.key);
})
});
Our primary interface here is the listenToUser method, which takes in a User object and begins listening on the correct channel for the "objectUpdated" event. When it receives that event, it schedules a method call to the _pushPayload method in the Ember runloop.
_pushPayload takes the message data and adds it to the Ember Data central store using the Ember Data pushPayload method. Because our application already speaks json:api, we don’t have to do any extra normalization.
Finally, we need to initialize this service and call listenToUser somewhere. I usually do this in the activate hook in the Application route, because this will be called whenever the application boots. Here’s how that looks:
// app/routes/application.js
import Ember from 'ember';
export default Ember.Route.extend({
currentUser: Ember.inject.service(),
pusher: Ember.inject.service(),
activate() {
this._listenToPusherEvents();
},
_listenToPusherEvents() {
const user = this.get('currentUser.user');
if (user) {
this.get('pusher').listenToUser(user);
}
}
});
This assumes that you have a currentUser service that is able to retrieve the the currently logged-in User model.
These two components wrap up the client-side implementation details.
There are also a few more things that you should consider on the client-side, including:
- What happens when the connection to Pusher is lost and the re-established, because the computer went to sleep or the user lost connection?
- What happens when a user logs in? You will need to call
listenToUserthere as well.
Conclusion
With these 4 small snippets, you can build in powerful real-time updates into your Ember applications backed by Rails. I use these techniques on Personal Network and a few other applications I’ve contributed to over the years.
One must appreciate how simple this is, in that we did not have to write any extra normalization logic on the server- or client-side to accomplish this. We used the existing conventions in Rails and Ember Data to make sure that the code for serializing, deserializing, and normalizing this data uses the same codepaths as our normal, HTTP-based data flows.
I hope you enjoyed this post and get a chance to implement it in your next project.
Drop me a note on Twitter if there’s a different approach that you take, or if you find any weaknesses in what I’ve outlined here.