In Pursuit of Correctness
All it takes is one zero on set to make the whole day worthless. —T.J. Misny
A friend of mine who directs films and commercials has this theory: All members of a crew on a film have a number between 0.0 and 1.0. The quality of the resulting product is simply a multiplication of everyone’s “factors.”
A great director of photography might be a 0.99. But if the craft services serve lunch two hours late, causing the crew to get grumpy, the product of their efforts might be a 0.6. 0.99 × 0.60 = 0.594. Your potentially great film became mediocre because of the timing of the food that your crew was served. If anyone’s efforts are a 0.00, you might as well have not shot that day.
This type of math is interesting to me when it comes to software. Not to apply such a ruthless measure to software teams, but to evaluate why correctness in components is important to the overall system.
Simple Views are Easy
While proving correctness is difficult, reasoning about it is tractable. Given monitoring tools like Sentry and others, we can see how many times our applications venture into unknown territory and crash. They 500 or raise an exception of some sort.
Reasoning about the correctness of this system might be as simple as looking at how many requests were served and how many resulted in a crash. Let’s say we served 10,000 requests and only 100 resulted in error. 1 - (100/10000) = 99%. Not too bad for a first pass!
We note this:

We obviously wish that things could be so simple. It’s not long before customers ask for more. Our application grows. It’s time to find a seam and extract a sub-system.
The Second System
Unfortunately, the team put on this project was a little rushed. They cut a few corners, and the extraction was not as clean as it could be. After shipping it to production and monitoring for some time, they calculated that 200 of every 10,000 requests fail for the new system. Their success rate is 1 - (200/10000) = 98%. Not great.1
We plug this into our little diagram that we use to reason about the world:

Our original component now relies on the extracted component, which is demonstrably of a lower quality. While both of these components look like they have not-too-bad track records, the customer sees the reliability of the system as a whole. The customer does not care if we use microservices; they do not care if our code is well-modularized.
The customer cares about their perception of the system, which is the product of its components. We do the math: 0.99 × 0.98 = 97.02%. Uhoh. We are definitely headed in the wrong direction.
Diamonds (of Death)
It would be nice if our software only contained 2 components. We would be living in simple bliss! Most software that does anything interesting has hundreds or thousands of modules.
Companies that embrace modularization at the service level may have hundreds of services, many of which they don’t know what they do or if they are important.
Drawing a graph of that size would be exhausting. Instead, let’s talk about the smallest interesting case in computer science: the dependency diamond. This is what separates the trees from the graphs, and where true programs are made.
Going back to our original example, these components are of varying quality. Let’s say it looks like the following:
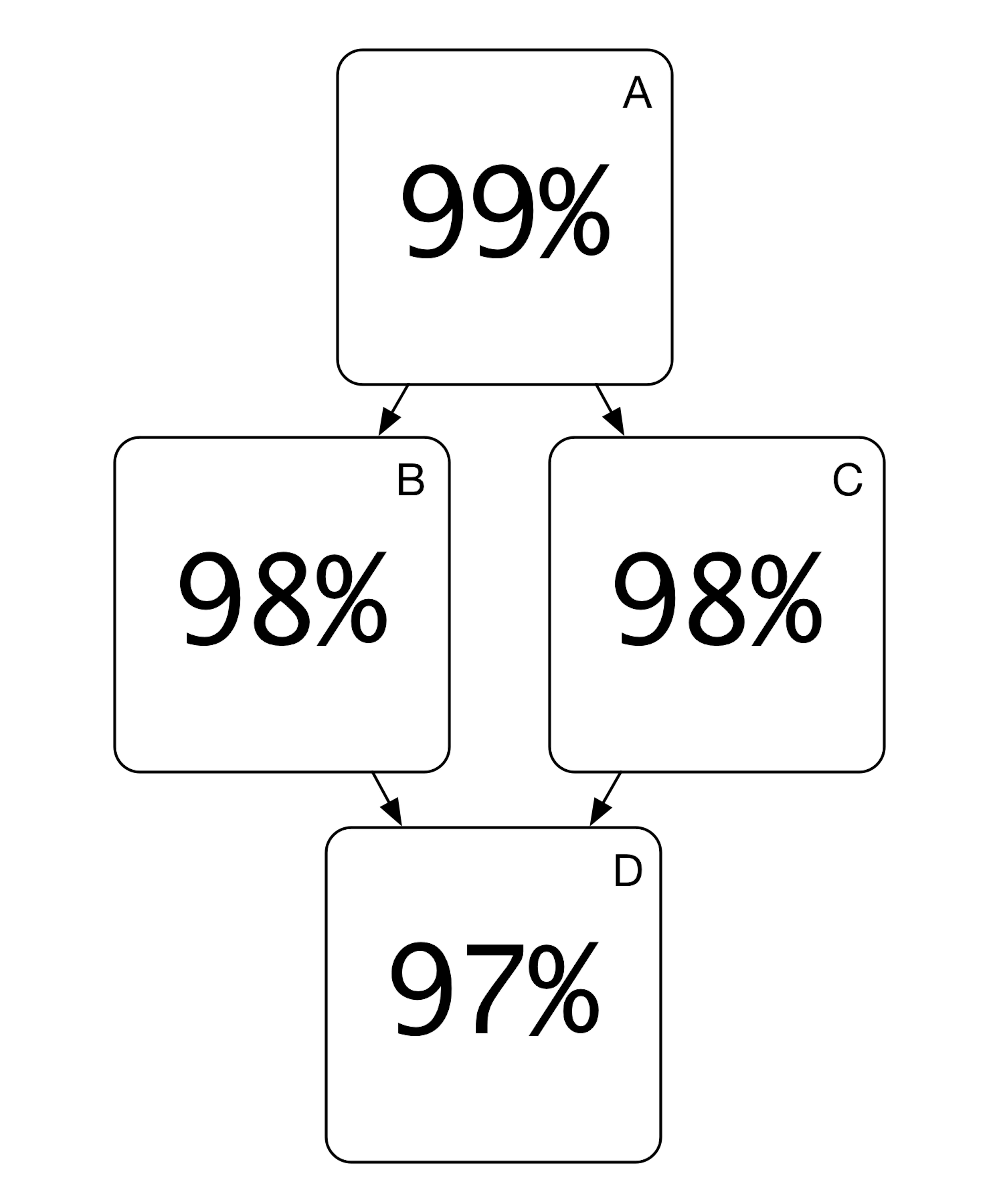
Our system has 4 components, whose layout form a diamond. I’ve labeled them to make discussion a bit easier. Let’s assume that each component also has a team: Team A, Team B, Team C, and Team D.
Before we dive into the mechanics of each team, let’s compute the user-perceived correctness of this system. Because the second layer is the same reliability, it doesn’t matter which route we take. The perceived reliability of the system will be: 0.99 × 0.98 × 0.97 = 94.11%. Woof.
Although each team does a pretty good job at their own component, the end-user result is less than satisfying. Furthermore, even if Team A executes flawlessly and achieves 100% correctness, they still have no hope of being better than 97% in the eyes of the user thanks to Team D.
Minus CAP and Many Other Things
This layout presents an overly simplistic view of software. It doesn’t take into account any sort of tradeoffs that you might encounter due to limitations of distributed systems. This example assumes a simple environment where our programs are executed.
Reading further, you may infer that incorrect components wired together in a distributed system produce much less reliable (albeit more hilarious) results.
What About Types? What About Tests?
We often looks for ways of hedging the above percentages. How can we write more correct programs? How can we inject some sensibility into the entropy of programming? Will types do it? Will tests?
Probably not.2 Types allow us to eliminate categories of errors, whereas tests eliminate specific examples of errors. Neither allow us to produce perfect code.
By finding a way to be defensive—whether through static typing or through rigorous testing—we can fudge the numbers a little bit. By rejecting invalid input early, the 1% to our 99% becomes “undefined behavior.” Sure, that might make our fellow teammates unhappy, but it should at least spark a conversation.
It’s for this reason that I often find myself making my inputs more strict, even in languages like Ruby. While Rails may not care if a model’s ID is 1 or '1', I do. Accepting strings to my method doubles the number of things I have to worry about!
Eliminating the types of valid inputs also decreases the surface area of our module. We don’t necessarily need types to do this.
Conclusion
Hopefully this post gives you a new way to reason about “How good should I make this class or component that I’m building?” Over-indexing on correctness and well-defined behavior early on can pay dividends later on. I’m always surprised how early the design stamina curve swings away from where I want to be.
Being “polite” and accepting different types of input (like strings and integers) has only bitten me in the ass.3 When needing to coerce user input into something sensible, always keep that adaptation layer separate from the core logic. Your core logic will remain simple, and if the user input gets better you can strip out the adaption layer easily.
I hope this gives you a new way to reason about your programs and maybe even make better ones.
Special thanks to Corry Haines, Justin Duke, Parker Moore, Alex Navasardyan, and Matt Lewis for providing feedback on early drafts of this post.
-
Great for me is, “If a plane operated this well, would I fly it?” If 98% of flights landed, no one would fly. ↩
-
For more on why, I recommend the talk “Ideology” by Gary Bernhardt. ↩
-
It’s simple at first, but then you start wondering how to coerce
'0.00','0.01','$1.50'and so on. ↩