Better Code Through Mutation Testing
I’ve always been on the lookout for using tests to drive a better understanding of the code that I write. Whether it’s making the code easy to delete or exploring Design Pressure, tests can have a remarkable effect on the quality of code beyond just making sure it works.
My latest explorations have led me to mutation testing. Mutation testing is a cousin to test coverage: it’s a way visualizing the relationship between production and test code. Traditional test coverage tools can be useful for very simple cases, but often don’t lead to the deep insights one would hope for. Test coverage tools merely tell you “Was this code executed while running my test suite?” That is, “Do the tests exercise this code?”
The problem with test coverage tools like this is that they report the line being “green” if it was merely executed. We can do better than that.
Enter Mutation Testing
Mutation testing is the act of mutating code to see if it still works, according to the tests.
If you change something and your tests are still green, you’ve learned something about your system: that piece is not covered by tests. This can be as subtle as moving a decimal point to the left or to the right just to see what happens. The goal is to make a change and have the code break.
Now, doing this for every bit of code would be tedious and take weeks, months, or even years. A relatively simple file can have thousands of different permutations. In Ruby, mutant provides syntax-aware mutation testing. It will divide things by zero, short-circuit conditionals, and more. This is great if you can roll it in early in the development process.
However, when dealing with legacy files that are hundreds or thousands of lines long, a true mutation testing suite is prohibitively expensive when it comes to time.
Deletion Testing
For my purposes when working with legacy code, I want to answer a much simpler question: “If I delete this line of code, will my tests fail?”
But I’m a programmer and I want the computer to do a lot of work for me. Let’s take it further: “Which lines of code in this file can I delete and my tests will still pass?” Basically, which lines are not being captured by the tests?
To accomplish this, I put together a little gem called crude-mutant to practice deletion testing.1 Deletion testing is a programmatic way of asking, “If I delete this, what happens?”
Using crude-mutant
crude-mutant will programmatically delete lines from a file of your choosing, and then run a test suite. It’s designed to be as simple as possible and to work well with *nix systems.
In your favorite shell:
gem install crude-mutant
crude-mutant "bundle exec rspec" app/models/company.rb
And here’s what you’ll see:
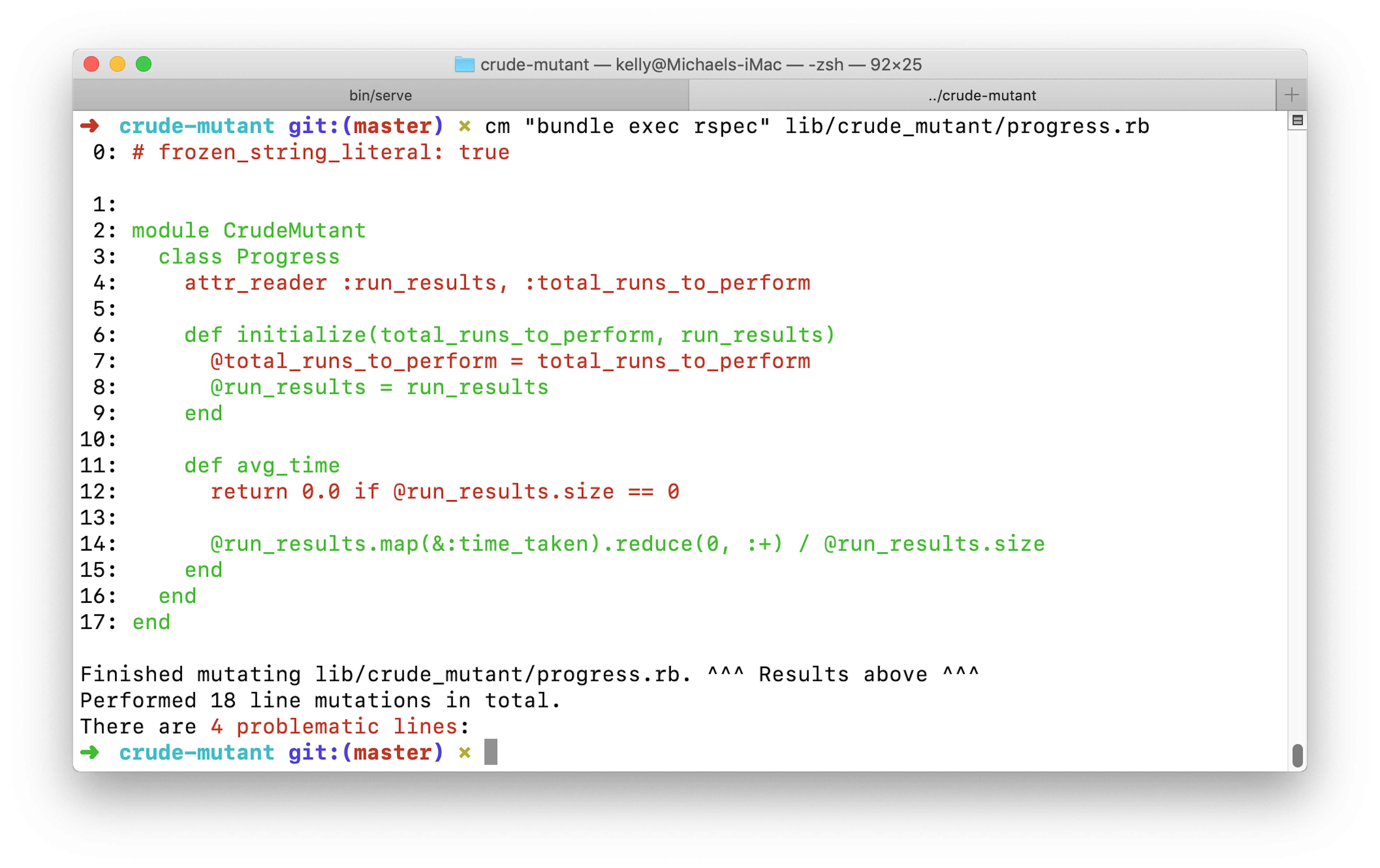
What you’re seeing is the files that are safe to delete and would still make your tests pass. Now, the crude-mutant is especially crude (but language agnostic!) so it’s going to say that removing the comments will still make your tests pass. It’s not wrong…
Why a Rubygem? Why not a bash script, or…?
Ruby is my native language, and macOS has Ruby support out of the box. The program is simple but is made much easier with certain data structures. Happy to entertain pull requests making the program work on other platforms.
What if my test suite takes hours to run?
The test command can be as simple or as complex as you’d like. I recommend isolating it down to just a few useful tests that you would expect to fail, and then going to go get a cup of coffee.
Conclusion
Give mutation testing and deletion testing a try. Hopefully it will result in strong code and some programmatic YAGNI.
It’s still early days for the gem. Please open any issues or PRs!
Special thanks to Iheanyi Ekechukwu and Julius Tarng for feedback on early drafts of this post.
-
Not an actual thing, but something I actually just made up. ↩