How to Break Apart a Rails Monolith
Scaling a Rails application requires patience and hard work.
Now, I’m not talking about the scaling challenges of “Ruby isn’t fast enough for my high frequency trading algorithm” but the “Our domain is so complicated that it’s difficult to model our behavior consistently as we grow.”
Given the realities of a business, software design cannot be a big GC pause for the organization. Instead, it needs to be happening all the time. The act of software design is always happening, whether we call it that or not. This post dives into how to apply this continuous design process to a large Rails application, probably one where the design hasn’t been considered beyond the Rails defaults for some time.
We want to better modularize a monolithic application to remove the accidental complexity, fix bugs faster, react to errors sooner, and on the whole develop a better product.
This post lays out the high-level questions to ask when choosing to modularize new or existing code within a large Rails monolith. This post is primarily concerned with the Ruby/Rails stack, but similar thinking may be applied to other technology stacks as well.
Please keep in mind that the following is the map, not the terrain. There will be real learnings beyond what can be captured in a post. Work with your team to navigate the treacherous details that might only appear as impressions on this map.
What does it mean to modularize?
There are many different ways to modularize code, such as extracting microservices, introducing private methods and classes, or using language/framework-specific tools such as Rails engines. The goal of modularization is to hide data and reduce dependencies. It seeks to answer the question: How can my part of the application know as little about the rest of the application as possible?
We want to reduce the knowledge among distinct parts of the application for a few reasons. For one, it makes the behavior more predictable: It’s clear where our module begins and ends. Next, it makes training new team members easier. Team members don’t need to load the entire application into their head before making a change. Finally, it makes it clear where problems exist when they inevitably come up.
It’s assumed that your Rails monolith is a large enough application that warrants a significant degree of modularization to continue to enable speedy development. The Rails framework and Ruby language do not always make modularization easy, so we need to get creative at times.
How should I modularize code within a monolith?
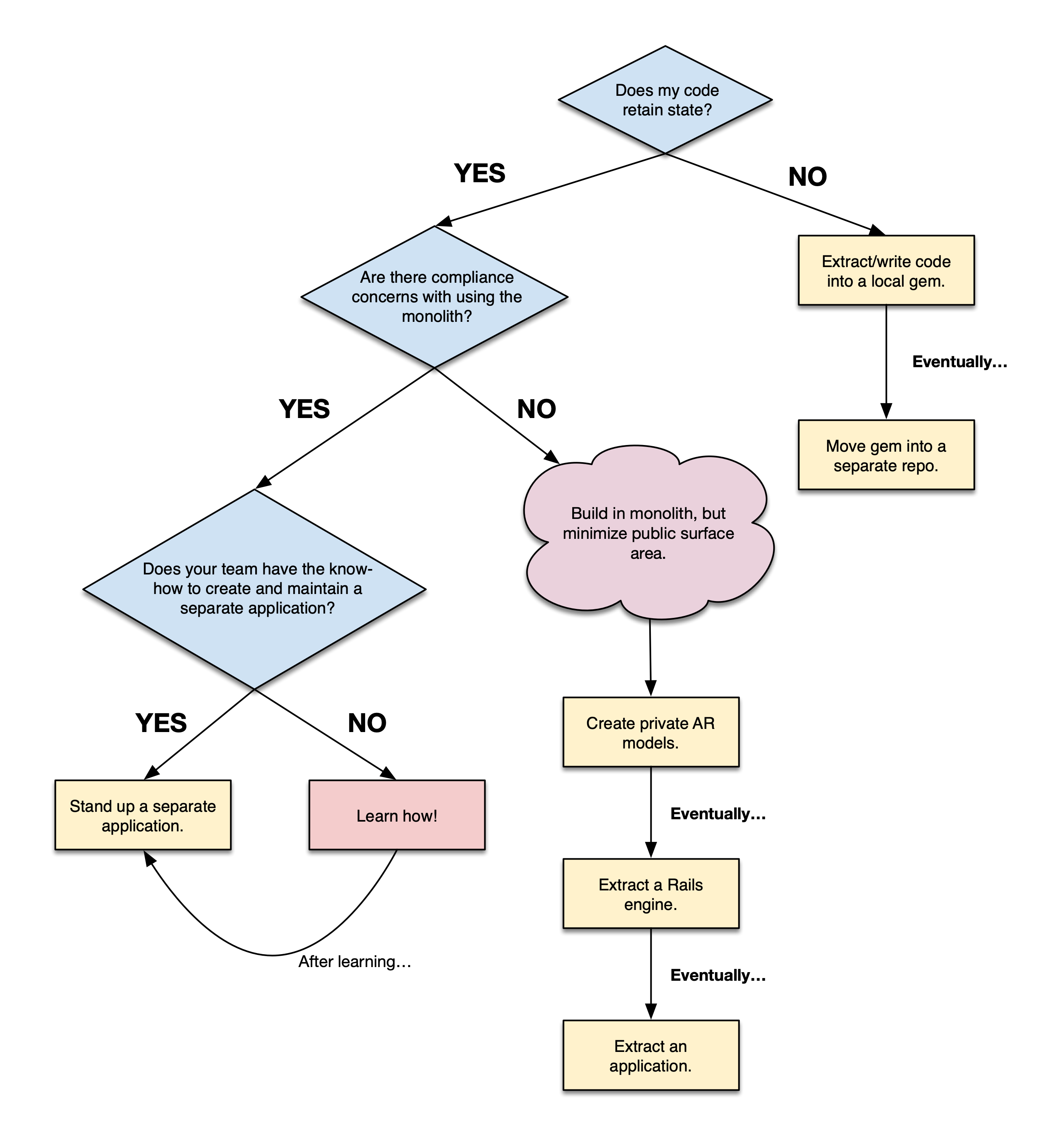
Breaking Down the Flow Chart
Let’s walk through each question within the flow chart above and provide some concrete examples and actions.
Question 1: Does my code retain state?
This is the first question to ask, since it can eliminate an entire heap of concerns and drastically simplify an effort.
If your code does not need to retain state (i.e. store something in MySQL or Redis) to be shared between web requests or Sidekiq jobs, you want to create a gem.
To create a gem, use bundle-gem. This industry-standard bundler utility allows for easy setup of a gem and its boilerplate. These gems can exist within the monolith for speedy development without needing to go through the gem publishing process or running your own gem server. Here’s how that looks in a Gemfile:
gem 'our_private_gem', path: 'gems/our_private_gem'
From there, put the contents of the gem at gems/our_private_gem.
If you do need to retain state between requests/jobs, you will need to move on to Question 2.
Before you move on, one more thing! You might be able to separate the parts of your app that retain state and don’t retain state.
Just because you need to store some data in the database does not mean you need to write off using a gem for modularization entirely. See if there are some complicated business processes or domains that could be represented as a stateless or just in-memory gem.
Before writing off the possibility of a gem, see if the problem can be split in two. Always try to minimize the amount of code that needs to be stateful. See also: Functional Core, Imperative Shell.
Recommendations:
- Gems should have standalone test suites configured as separate jobs within your CI platform.
- Gems may live in the monolith or be extracted into their own repo. Working with a local gem within the monolith is a good stepping stone for extracting a gem.
- Gems must be careful requiring dependencies. Generally, dependencies should be as loose as possible. Gems with strict dependencies make upgrading dependencies in the monolith a pain.
- Gems must not monkeypatch Ruby standard classes or other objects. This makes including the gems not have side effects on core Ruby classes.
- Before moving code into a gem, you may transform it in place to improve the code structure.
Question 2: Are there compliance or scaling concerns with the data I will be retaining?
Not all data is created equal. Some new functionality may have different compliance requirements than the application today. On the other end of the spectrum, it might be clear that the primary database just isn’t a good home for the data. That would be the case for some analytics-shaped or document-shaped data.1
For this, the discussion will primarily hinge on the capacity of your infrastructure team to stand up new applications.
While it can be enticing to spin up a new service, I would not recommend doing this for solely ergonomic reasons. Default to building new functionality within the monolith, only extracting once the problem domain is understood.
Recommendations:
- Standing up a new application is no small feat! You’ll need to set up logging, exception handling, paging, health checks, deploy pipelines, CI pipelines, a new database, and more.
- Separate applications may have many ways to communicate with the monolith, including HTTP, Kafka, gRPC and more. Try to pick one communication protocol and stick to it.
- When standing up a separate application, only one application should know about the other. Either the monolith knows about the new service, or the service knows about the monolith. I call this the “Stripe test.” If we are integrating with Stripe, how much does Stripe know about our data models? The monolith may need new APIs for communication, and may need new outgoing streams (like webhooks) to communicate back to your new application. Adhering to this helps prevent circular dependencies and keeps our architecture simple and easy to change.
No compliance/scaling concerns, I’m building within the monolith!
If you do not have compliance or scaling concerns prohibiting data sharing with your monolith, building within the monolith is the safest route. When building something new within the monolith or refactoring existing code, the goal is to make the code easily extractable in the future through modularization and data hiding. These goals require us to throw some Rails defaults out the window.
When developing a new module, whether via a Rails engine or through private ActiveRecord models with service objects as interfaces, we need to uphold a single principle as we develop: Our code should know next to nothing about the monolith, the host application.
I recommend starting off with private ActiveRecord models because the technique is the most lightweight way to achieve data hiding within the context of the monolith. What does lightweight mean? It won’t require any additional CI setup, migration-copying configurations, or dependency management.
Using private ActiveRecord models with service objects as interfaces allows developers to be very specific about the expected and supported actions a user may perform with certain subdomains. This might be as simple as “create” and “delete” actions, which might effective-date and only soft-delete information behind the scenes. We do this because default ActiveRecord behavior exposes hundreds of potential operations with near-complete access to the object graph. It hands the user the kitchen sink.
I recommend starting with private ActiveRecord models before upgrading to a Rails engine.
Recommendations (Private AR Models):
- Use namespaces and
private_constantto hide ActiveRecord models from users. - A litmus test for this: If you can swap out usage of ActiveRecord for something else and not have to change any external call sites, you are doing well.
- You will need to reopen the module within the test context to test private classes. I normally look to avoid reopening modules within test files because doing so modifies production code. In this specific case, it is okay.
We’ve got some related private ActiveRecord models, now let’s extract them into a Rails engine!
After we have gotten to know the domain better through private ActiveRecord models in production, we might start to see a design emerge. We may wish to further codify the separation of the domains by extracting a Rails engine.
A Rails engine is a primitive provided by the Rails framework to encourage modularization. Rails engines do not guarantee crisp modularization because of Ruby’s global namespace. When creating Rails engines, we still need to be mindful of any circular dependencies we may draw.
This will look like several interrelated models that are in constant coordination. There might be a dozen or so models with a handful of well-defined, well-tested interfaces.
Recommendations (Rails Engines):
- The test suite for Rails engines must be able to be run in isolation.
- The Rails engine must not use the global namespace to “reach back” into the the monolith application. If the engine needs a class from the monolith, that dependency should be injected upon initialization.
- The Rails engines guide recommends and demonstrates using classes from the host application. I do not recommend doing this, as it draws a circular dependency. The host app knows about the engine via its Gemfile, and the engine knows about the host app through the classes. This makes testing in isolation nearly impossible.
- Rails engines must be careful requiring dependencies. Generally, dependencies should be as loose as possible.
We’ve got a healthy Rails engine, let’s extract an application!
On a long enough time scale, and if the design of our Rails engine is stable, it might make sense to extract an entirely separate application. This would allow for independent deploys, test suites, and operations. The differences here are both upsides (faster, more predictable iteration) and downsides (needing to maintain a separate application).
We measure the success of our design and modularization efforts by how little time it takes to extract into a separate application. If moving our engine into a separate application takes a few days (standing up a new service and migrating data without changing any calls in the monolith), we’ve done good.
Give things a few months to cook as an engine to see if your team would benefit from extracting an engine into its own service.
Conclusion
This is an extremely high level map to help navigate the long process of breaking apart a monolith. There will be dragons and danger on this adventure.
I particularly like the approach above because it is iterative. You can stop at any time and the application will be left in a more organized state. Swapping out one technology for another—going from HTTP to gRPC for example—is simple because the interfaces are well-defined. This approach allows us to delay architecture decisions to the last possible moment.
Good luck!
Special thanks to Matan Zruya, Emily Field, Supreet Singh, Jack Danger, Markus Schirp, Ajaya Agrawalla, Kevin Brown, and Kent Beck for reading early drafts of this post and providing feedback.
-
For a good story about this, I recommend ready the case studies from my other post “A Framework for Making Product-Technology Decisions.” ↩