From 25 Minutes to 7 Minutes: Improving the Performance of a Rails CI Pipeline
This article is also available in Mandarin (普通话).
We recently hit a new record at Gusto: 6 minutes and 29 seconds.
That time is how long it took to run the test suite for our largest application at Gusto, a Rails monolith. This is the fastest our continuous integration (CI) had ever run in the company’s recent history. This last time our CI suite ran this fast, the whole company could fit in a conference room. Now we’re several hundred engineers located around the world working out of a Rails monolith that powers 1% of U.S. small businesses.
For Gusto, having fast CI is more than just a luxury. We view it as a competitive advantage. When Congress passed the Paycheck Protection Program during the Coronavirus outbreak, minutes mattered when it came to helping customers secure funds to keep their businesses alive. The sooner we could deploy code, the more likely our customers would be able to tap into the available funds.
As we’ve increased CI speeds, we’ve seen engineer productivity increase as well. For every minute that we improve CI times, Gusto lands 2% more Pull Requests per engineer per week.1
For the purposes of our work, we had a simple goal. We wanted to make the speed of our test suite a function of one parameter: How much are we willing to spend? Simplifying our infrastructure to this point makes it much easier to make cost-benefit analysis. We can put a dollar amount on 5-minute builds vs. 7-minute builds.
This blog post covers how we went about speeding up our test suite. We have a Rails monolith with a JavaScript single-page application (SPA) written mostly in React. The lessons learned here will dive into the specifics of our Ruby- and JS-based technologies, but should be generally applicable to all slow test suites.
Overview
My colleague, Kent, says there’s 3 steps to building software:
Make it work
Make it right
Make it fast
We use this everywhere, from assessing code when interviewing candidates to building our software day-to-day. The order is important.
“Make it work” means shipping something that doesn’t break. The code might be ugly and difficult to understand, but we’re delivering value to the customer and we have tests that give us confidence. Without tests, it’s hard to answer “Does this work?”
“Make it right” means that the code is maintainable and easy to change. Humans can read it, not just computers. New engineers can easily add functionality to the code. When there’s a defect, it is easy to isolate and correct.
Finally, we “make it fast.” We make the code performant. Why is this last? For a FinTech company like Gusto, doing the wrong thing quickly is a good way to bankrupt us and our customers. Not good! Not every piece of code needs to be performant. It’s a shame to work with “performant” code that is difficult to read that might only be executed once per day.
We’ll be applying this mantra to how we made our CI suite faster.
Making it work
Eliminating test flakes
Eliminating flakes in your test suite must be one of the first things you set out to accomplish. A test flake or a flaking test is a test that has a non-deterministic result; it sometimes passes, sometimes fails. Having a fast-but-flaking test suite does not give you the confidence that your code works. It’s just a coin flip.
To eliminate flakes with a large engineering team, we adopted and enforced the following policy:
All tests that fail on the master branch will be considered flakes. These tests will be marked as skipped. Teams owning the tests that flake can fix them and unskip them at their own leisure.
This policy allows the test suite to stay green while letting individual teams decide when they would like to put in the effort to write more deterministic tests. They may choose to do so right away, or delay until they work on the feature again. This approach decreases the collateral damage that one team’s non-deterministic tests have on other teams.
Introducing this policy was not without discussion. “What if we skip an important test?” was the most common question. This is an important question, but we need to keep in mind the context. The test is being marked as skipped because it has randomly failed. How much confidence do we have in that test and feature in the first place. Many times, the tests flaked because there are actually bugs in production!
This policy alone took our green build rate on our master branch from ~75% to 98%!
Make it right
Get back to the defaults
Over time, we had drifted away from the default way of running RSpec tests. Adhering to the defaults is hard. It’s the testing equivalent of eating your vegetables. Here are a few of the defaults that RSpec imposes:
- State is reset in between each test case. This makes sure that tests are repeatable, deterministic, and not reliant on each other.
- Test execution is randomized. This helps suss out test pollution by making sure that tests are not interdependent.
- Test files use the Rails autoloader. This means we only load the parts of the application that we need, not the whole thing. This also helps suss out incomplete test setup.
Re-adopting each of these defaults was an effort. Making sure each test case resets its state—the database, Redis values, caches, etc.—would surface new test flakes. Depending on the nature, we’d either fix the change or classify the previously-working test as a flake.
We slowly reintroduced the RSpec defaults, which set the stage for improving the speed of our tests.
Make it fast
Introduce a maximum-allowable test time
Our tests are lopsided. Some test files used take milliseconds to execute, others used to take tens of minutes. The tests taking several minutes were integrated tests clicking through some of our most important flows in the app. We wanted those faster, but we didn’t want to remove them.
Because we would eventually rebalance our test suite across many nodes, we would quickly hit a bottleneck. Our test suite would only be as fast as our slowest test file.
So we implemented a new policy:
No test file may take more than 2 minutes to execute.
This threshold was pulled out of thin air, but seemed pragmatic enough. We only had 40-ish files that took more than 2 minutes.
Once the policy was in place, we began tackling the existing slow tests to bring them under our new threshold. We rolled up our sleeves and brought those 40 files below the threshold. From there, it’s become the responsibility of individual teams to make sure their test files do not take more than 2 minutes to execute. A test file that takes more than 2 minutes to execute is marked as skipped.
Balance tests based on worst-case scenario
At this point, we have a reliable test suite that’s slow. It can execute tests in any order it chooses, but its method of allocating tests to nodes is random. We have some nodes finishing in seconds and others taking tens of minutes. How can we get those to even out?
Our final problem is one of test balancing. We evaluated two solutions here:
- Develop a queue that would feed test cases to nodes when they were ready. While the most fundamentally sound, this is not compatible with RSpec without a great deal of upgrades to the framework. Furthermore, it introduces shared state among all of the different parallel jobs.
- Record test timings in a database, at the beginning of a CI run, split the tests into different buckets aiming for all groups to be the same length. We went with this approach.
We went with the record-and-bucket approach to doling tests out to nodes because it fits nicely with the knapsack gem. This record-and-bucket approach also doesn’t share state during the test runs among many different parallel jobs. This is important because a shared queue could have hundreds of nodes each requesting new work thousands of times per second for a single build.
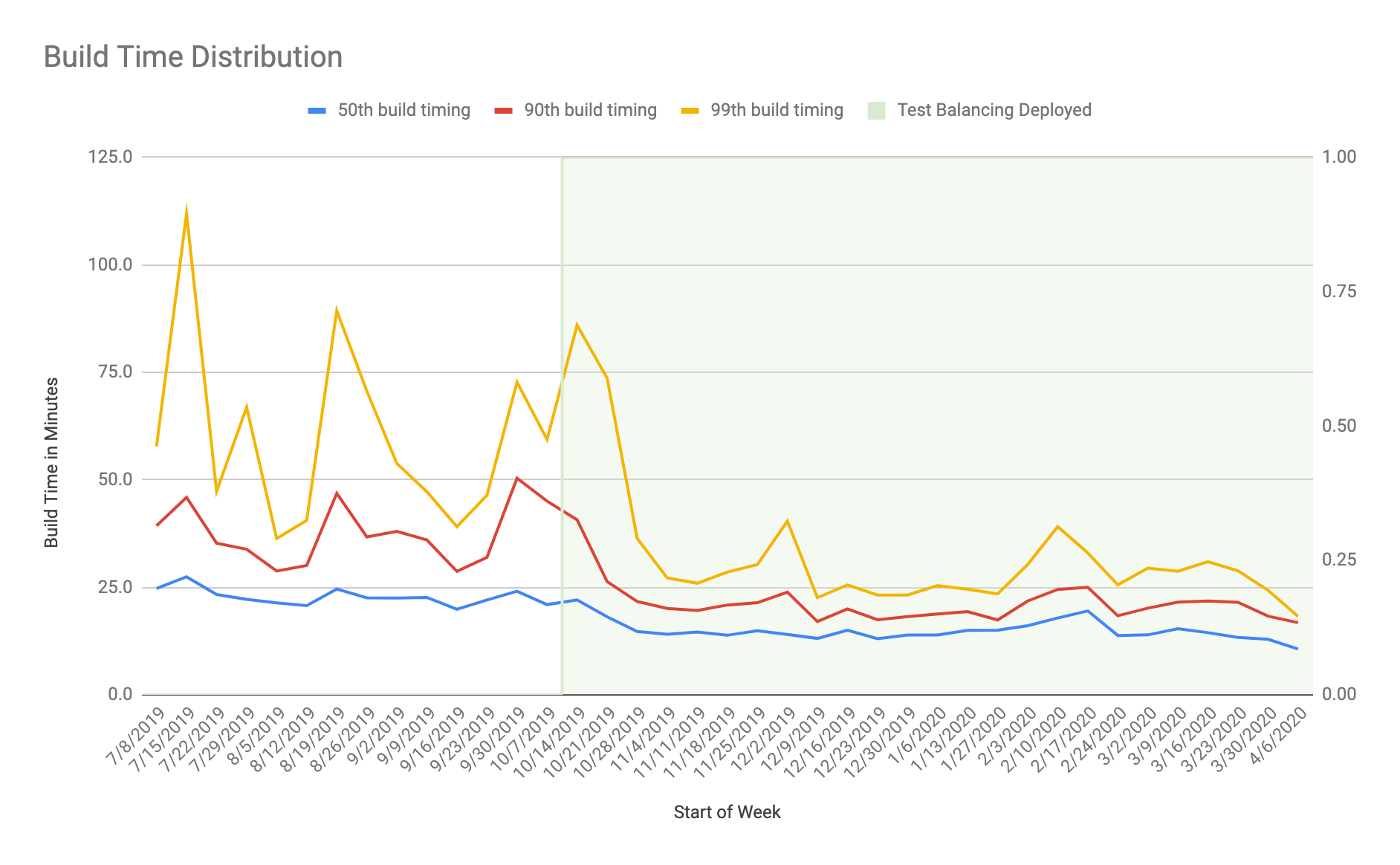
So we stood up a MySQL instance that now records test timings for all files. At the beginning of each CI run, it generates a knapsack file based on the 99th percentile time of each test file. At the end of each CI run, it uploads new results.
Why 99th percentile? Because we run our CI on shared hardware (AWS), we don’t have control over the underlying infrastructure. We would see test timings swing wildly for individual test files. We could not correlate these swings to the EC2 instance types we used nor any other parameter we could measure.
Rather than perfecting our build infrastructure, we made our system resilient. By using the 99th percentile to organize tests, we guarantee “no worse than” performance rather than a good average performance with outliers. As the underlying hardware changes or we see blips at the infrastructure layer, our CI pipeline retains predictable performance characteristics.
Once implemented, this gave us a self-balancing system. As more tests ran, our test balancing would get more accurate. If certain tests got slower over time, the buckets would balance out accordingly.
Finally, increase parallelization
And now came the fun part: making things truly faster.
To do so, we only needed to change how much parallelism we wanted. We’ve gone from 40 parallel jobs to 130 since we began this project. This has resulted in a slightly more expensive bill, but much faster CI run times. We use Buildkite for CI infrastructure at Gusto, but the concept of parallelization exists within all major CI products.
Although we increased the parallelism by more than 3x, our CI bill has not increased by the same factor. Why? We’re simply making better use of the CPU time we were already using. By balancing evenly across nodes, we are using the same number of total CPU minutes but in shorter bursts.
Conclusion
Throughout the past few months, we’ve steadily made the CI pipeline for our main application at Gusto less brittle and much faster.
The upkeep for this is still a daily effort. We still skip flakes as they come up, or find new tweaks to speed up our builds. Hopefully this post serves as a roadmap for your own teams to improve your CI pipelines and release infrastructure, regardless of the technologies you use.
If you have any questions, I’m happy to answer any on Twitter!
Special thanks to Alex Gerstein, Kevin Brown, and Markus Shirp for reading early drafts of this post and providing feedback.
-
This is only a correlation. We might also just be drinking better coffee. ↩