So You Want to Store a File…
…but where do we put it?
Choosing where to store files for a web application can be a surprisingly daunting task. This is a common question at work and a question I’ve heard throughout my career. I’ve developed an expertise on exactly this topic by founding a company that was GitHub but for designers, by working at a CDN, and today by working at a company that effectively turns user input into lots of PDFs. (We also move a few basis points of the money in the United States every year, but that’s easy.)
This post will dive into the how’s and why’s of storing files online, starting with a little history lesson. You will learn some sane defaults for securing and serving these files, regardless of language or framework used. This post will use Amazon’s cloud products as short-hand, but most cloud providers will have analogues to Amazon’s offerings.
In the Beginning…
In the Old Days before Amazon Web Sevices and cloud computing, scaling web applications was difficult. This was made even more difficult when dealing with different shapes of user data.
We can put small bits of relational data in our database, but where do we put these big files?
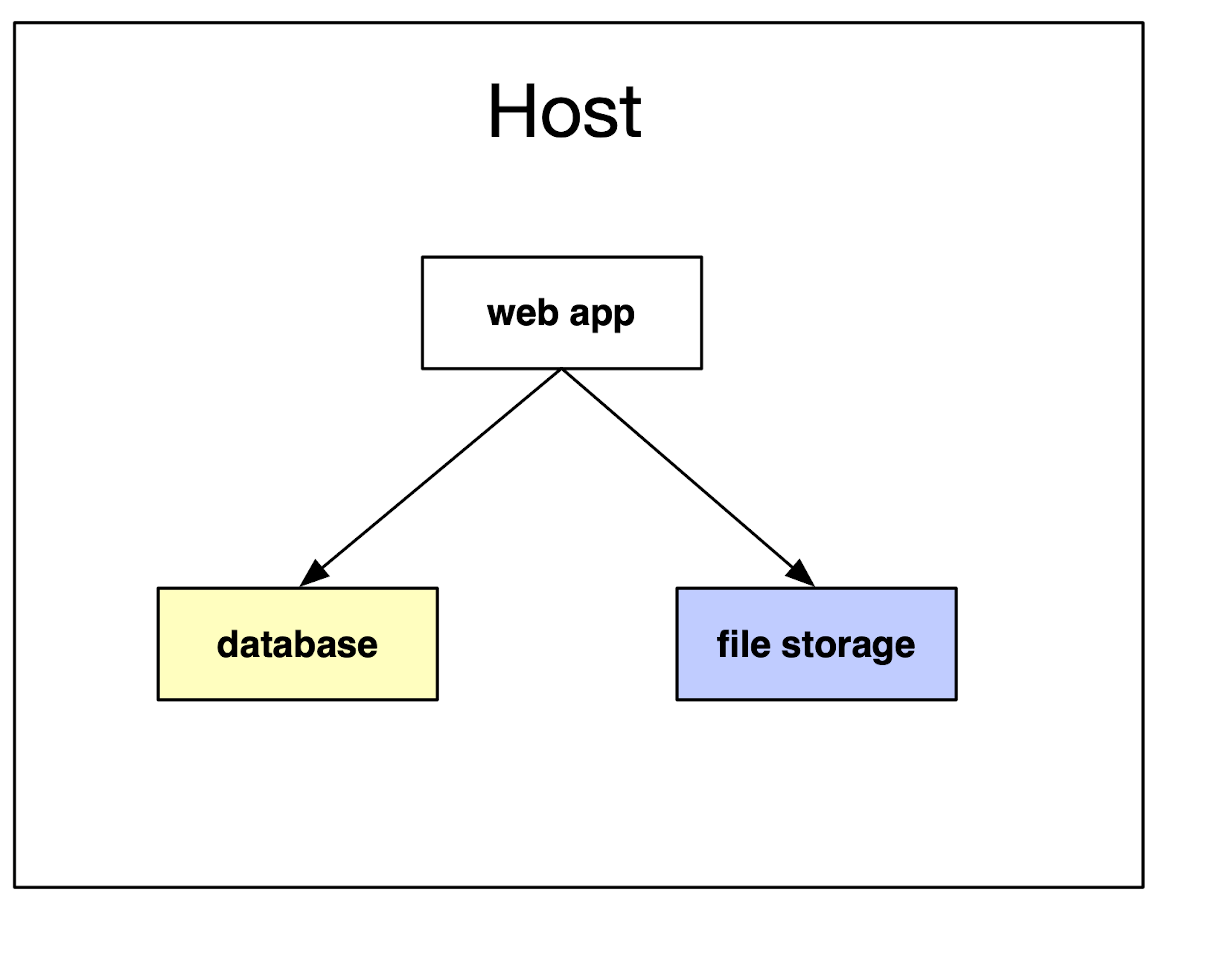
For some time, you would likely locate them on the same host. But this wouldn’t scale forever. For the same benefits we see of moving the database onto a different host, we get similar benefits of moving file storage elsewhere.
So, many companies would be a file storage system outside of their main web application servers.
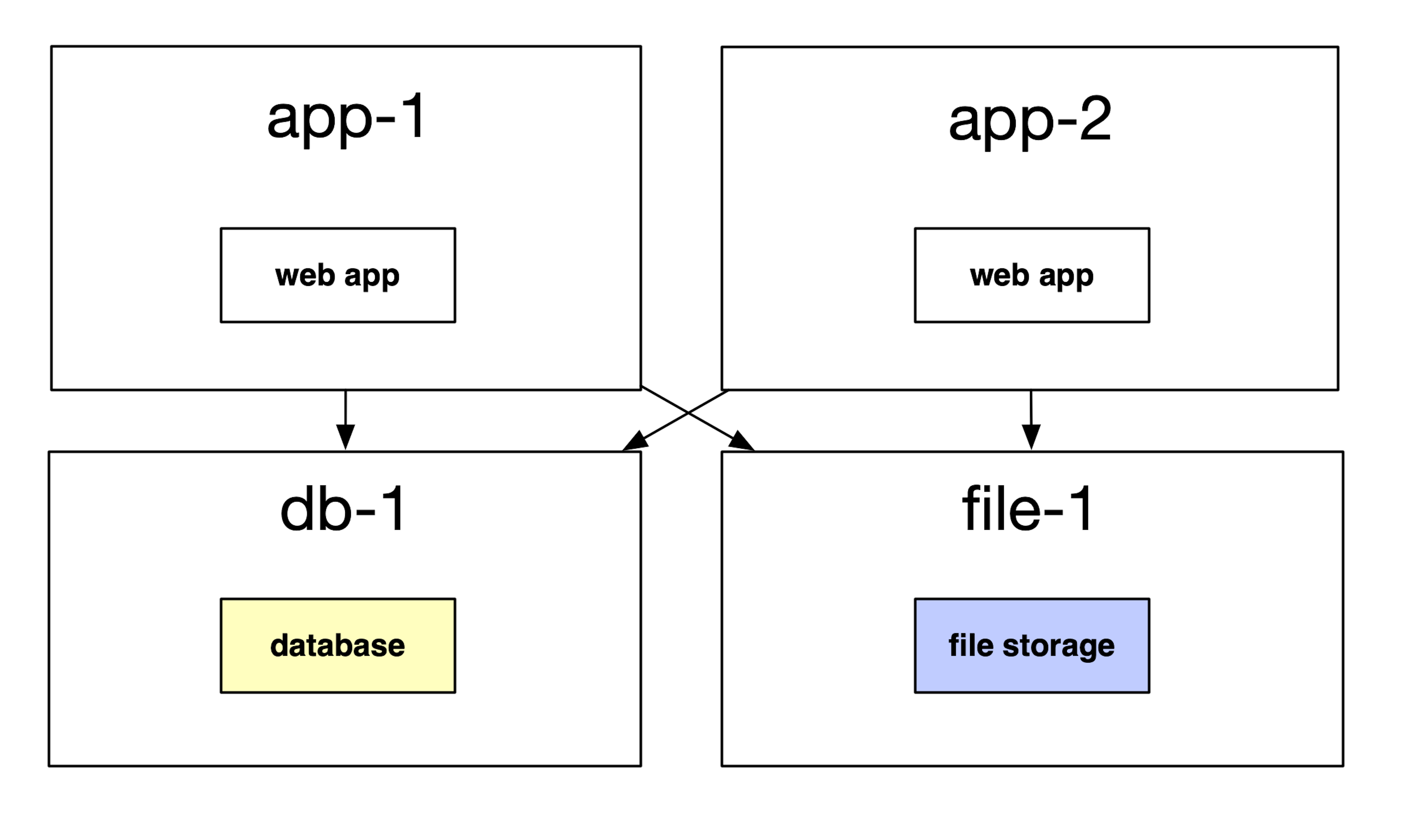
This enabled a few nice properties for web applications:
- As we receive more traffic, we could scale our web application servers without worrying about data storage.
- We could put a separate team on maintaining our file storage system. This is good, because storing files can be much different than serving web requests; we need to think about durability, availability, backups, and more.
In 2005 and 2006, a few bright engineers at Amazon likely realized two things:
- Storing lots of files was a full-time job with lots of difficult problems to solve.
- Every web application needs this.
Thus, Amazon’s Simple Storage Service (S3) was born. Fast-forward to today, it’s the de facto hard drive in the sky.
So You Want to Store a File…
So where does that leave you today? For most web applications, you need two things:
- An S3 bucket for storing and serving public data.
- An S3 bucket for storing and serving sensitive data.
This post will not dive into the concerns of larger ETL systems or data pipelines. We’ll keep things to just the web applications.
We’ll be operating with the following principles and assumptions for the rest of this post:
- These are best practices as I know them today.1
- A logical separation between sensitive and non-sensitive information is desired because it makes the securing data easier.
- We do not want any orphaned objects.
- We want to enable the fastest retrieval of these files to enable the best customer experience.
Storing and Service Public Data

Public data here can also be known as insensitive data. The data here will likely be the following:
- Asset files. JS, CSS, images and more.
- Template files that you might provide to your customers. These could be code snippets, CSV templates, or something else. They don’t change that often, and many downloads don’t hurt.
- Miscellaneous files that you provide as downloads, think Terms of Service PDFs, etc.
We also operate under the assumption here that leaking a URL will not be harmful to the business or the customers. If someone gets ahold of a URL, is customer data compromised or does it create a headache for the business? If so, you will want to see the section on Storing and Service Private Data.
The tool we’ll use to adhere to the above principles will be the asset pipeline.
Use an Asset Pipeline
An asset pipeline is a tool for turning some of the files within a code repository into files ready to safely be served via a CDN.
I have the most experience with Sprockets and Webpack, both of which are bundled into the Ruby on Rails framework at the time of writing.
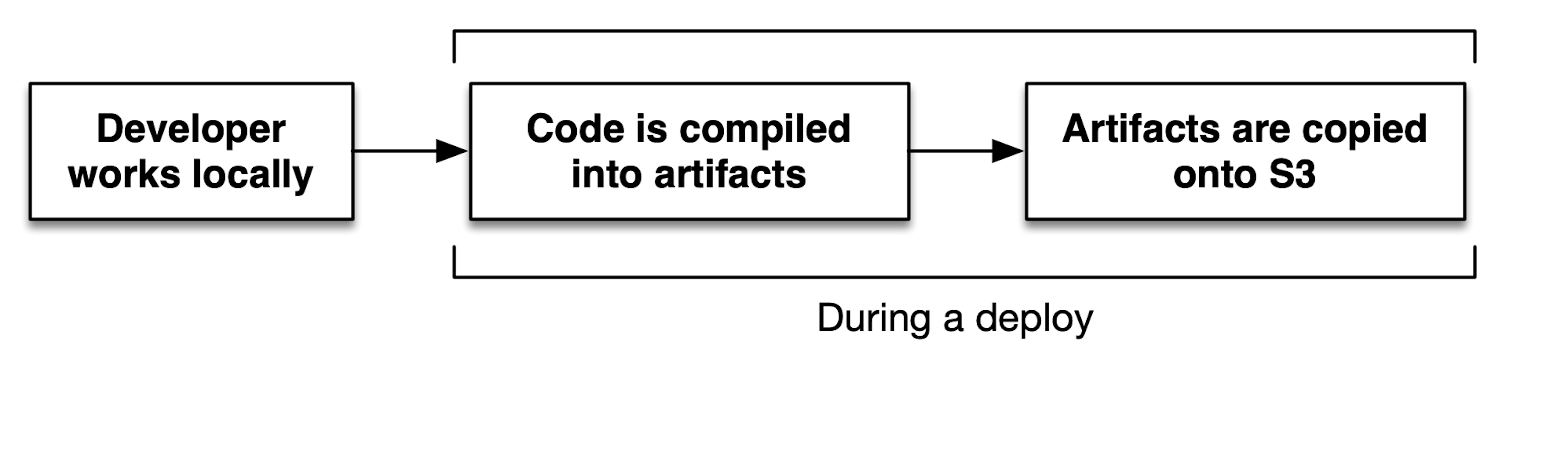
Here’s how asset pipelines work:
- Developers work on code within a repo.
- Through a “compile” step, that code is transformed to be better suited for production. This usually means minification for JavaScript, and could mean compression for some large images.2
- When code is compiled, assets are usually fingerprinted with the checksum of their contents. This helps ensure that customers receive the correct version of an image, JS bundle, etc. and not a stale one. A fingerprint might look like this:
2a8db3f8. - “Deploying” these artifacts is usually as simple as copying files to an S3 bucket.
Asset pipelines provide the following benefits:
- Using an asset pipeline prevents orphaned objects. Because all artifacts are derived from code and assets within a repo, we know where each one comes from.
- Files while developing can look different from being served. We can optimize for the developer and customer experience at the same time.
- Because the asset pipeline prevents orphaned objects, we could delete all objects in our assets bucket and reupload them quickly.
If you are serving any sort of assets from your web application (JS, CSS, images), take the time to set up an asset pipeline.
Use a CDN
Because these public files are likely to be downloaded repeatedly, we want to use a Content Delivery Network (CDN).
CDNs help deliver the best customer experience possible by moving the files closer to your customer. They are a clever hack to overcome the limitations of the speed of light. Files located closer to the client are served faster.
Most CDNs operate as a “reach-through” or “pass-through” cache. This means that even if your CDN node does not have a copy of the file requested, it will go fetch it and store it according to the relevant HTTP headers.
Using a CDN will create a line item on your infrastructure bill, but it will keep your application snappy and greatly improve the customer experience.
There are entire books written on the topics of CDNs
If you’re using the Amazon stack, CloudFront is their CDN product.
Upgrade: Make These Files Private
If you are looking to further upgrade your defaults here, you can use Origin Access Identity (OAI) to allow CloudFront requests while disallowing direct S3 requests. This restriction ensures that these public files are only served through your CDN layer and not through S3.
This ensures that the customers will always have the best experience, regardless of mistakes in configuration. (I’ve seen folks unknowingly serve files off of S3 instead of serving through CloudFront.)
Let’s now move on to storing and serving sensitive data.
Storing and Serving Sensitive Data
Alright, so what do we do with sensitive data?
This might be data that is secret to the company, or that would be bad if other users were to see each other’s files. Almost everything a user uploads (including profile photos), should be thought of as sensitive data. This might also include large blobs of data generated by the application, such as JSON blobs or other data unfit for storage in a traditional relational database.
Although the data is sensitive, we can still serve it publicly although a bit differently.

Our primary tool for storing and serving sensitive data will still be S3, but we need some help. We need to use a library to help organize the data, retain a record of it, and securely serve it back out when requested. We’ll talk about two Ruby gems for accomplishing that: Paperclip and ActiveStorage in this post.
These libraries are both designed to use the local disk during development for file storage but use a cloud provider in the production environment. They enable this without making any code changes, just configuration changes!
Using the Libraries
Both ActiveStorage and Paperclip need to work in tandem with the database to keep a record of where files are stored. Paperclip is currently deprecated, but it’s already in use at many Rails companies so I cover it here.

Paperclip does this through 4 database columns. By keeping a reference to objects on S3 in the database, we ensure that no objects are orphaned. Given a User model attribute named profile_photo, we would create the following 4 database columns on our User:
profile_photo_file_name(string)profile_photo_content_type(string)profile_photo_file_size(number)profile_photo_updated_at(datetime)
By storing these 4 bits of information, we can turn this:
user = User.first
user.profile_photo.expiring_url(5)
into this:
"https://my-bucket.s3.us-east-1.amazonaws.com/profile_photo/123.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20130524%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20200524T000000Z&X-Amz-Expires=86400&X-Amz-SignedHeaders=host&X-Amz-Security-Token=IQoJb3JpZ2luX2VjEMv%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaCXVzLWVhc3QtMSJGMEQCIBSUbVdj9YGs2g0HkHsOHFdkwOozjARSKHL987NhhOC8AiBPepRU1obMvIbGU0T%2BWphFPgK%2Fqpxaf5Snvm5M57XFkCqlAgjz%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDQ3MjM4NTU0NDY2MCIM83pULBe5%2F%2BNm1GZBKvkBVslSaJVgwSef7SsoZCJlfJ56weYl3QCwEGr2F4BmCZZyFpmWEYzWnhNK1AnHMj5nkfKlKBx30XAT5PZGVrmq4Vkn9ewlXQy1Iu3QJRi9Tdod8Ef9%2FyajTaUGh76%2BF5u5a4O115jwultOQiKomVwO318CO4l8lv%2F3HhMOkpdanMXn%2B4PY8lvM8RgnzSu90jOUpGXEOAo%2F6G8OqlMim3%2BZmaQmasn4VYRvESEd7O72QGZ3%2BvDnDVnss0lSYjlv8PP7IujnvhZRnj0WoeOyMe1lL0wTG%2Fa9usH5hE52w%2FYUJccOn0OaZuyROuVsRV4Q70sbWQhUvYUt%2B0tUMKzm8vsFOp4BaNZFqobbjtb36Y92v%2Bx5kY6i0s8QE886jJtUWMP5ldMziClGx3p0mN5dzsYlM3GyiJ%2FO1mWkPQDwg3mtSpOA9oeeuAMPTA7qMqy9RNuTKBDSx9EW27wvPzBum3SJhEfxv48euadKgrIX3Z79ruQFSQOc9LUrDjR%2B4SoWAJqK%2BGX8Q3vPSjsLxhqhEMWd6U4TXcM7ku3gxMbzqfT8NDg%3D
&X-Amz-Signature=JohnHancock"
Don’t worry about what all of that means, we’ll get to that shortly.
ActiveStorage takes a more generalized approach, separating the idea of file storage from the model files themselves. It also has the ability to sign URLs. It’s design also ensures that no objects are orphaned.
By using either of these libraries or an equivalent in another language, we ensure that we never have orphaned objects. Orphaned objects are cumbersome because they add to the costs and can be security concerns. We should be able to answer for every byte of data we store in S3 or be able to safely delete it.
Storing Information Securely
Whether using Paperclip or ActiveStorage with Amazon S3, all user-uploaded content should be stored with the private Access Control List rule. This means that anyone who happens to get a URL will not be able to access the object, unless the URL is re-signed.
This shrinks the window in which URL sniffing becomes a security issue. Someone getting a URL must act on it immediately. More on that in the next section.
Signing URLs
Although files may be set to private on S3, users can still download them with the right secret handshake. That secret handshake is what’s known as a signature. URLs with a signature are known as signed URLs and have a time in which they are valid encoded within them. This means that a signed URL might only be good for a few seconds before it will need to be resigned.
In my above example, my example is good for 5 seconds. Every Paperclip::Attachment object stored on S3 has an #expiring_url method. ActiveStorage has a slightly different means of securing URLs that won’t be covered here. Instead, check out the docs.
These should be set as defaults for your chosen library’s configuration and the expires_in value should be set to be as low as possible. In most cases, less than 5 seconds is fine.
It is these signed URLs that we will send to the client so that they may securely and temporarily access sensitive data.
More Secure?
In almost all cases, redirecting to a signed URL after authenticating and authorizing a user will be enough to keep sensitive data secure.
If the possibility of a sniffing and replaying is enough of a concern for your company, you can always stream the files within your web application to clients. I usually do not recommend this, since it ties up web application servers.
Antipatterns
I consider the following antipatterns for file storage within web applications:
- Storing files unrelated to the application. “We have this one bucket already set up, let’s just put this file there.” Files should go in the buckets owned by the application they logically belong to. No dumping grounds.
- Manually uploading any file via the AWS web console to an S3 bucket for the purposes of serving to customers. Files should be uploaded via our asset pipeline (non-sensitive) or the application itself (sensitive).
- Interacting with S3 directly in the code. The deploy scripts with our asset pipelines and the configuration for libraries like Paperclip will be the only places in our application code where we refer to S3 resources directly.
As with anything, there will be exceptions to the above rules.
Other Considerations
- For social networks where user-uploaded content might be high traffic and less sensitive, you probably want to instead use a CDN for sensitive files.
- If you find yourself doing a lot of mutation on image files, use an on-the-fly image manipulation CDN like imgix.
Conclusion
This post is a rough sketch of the how’s and why’s of storing files in a web application. Even for the smallest applications, hopefully you find the cost of this setup to outweigh the benefits. Setting these defaults early in an app’s life can save time, money, and headache down the line.
If you have any changes you’d like to see in the recommendations above, please send them to me via email or reach out on Twitter.
Special thanks to Shayon Mukherjee and Sneha Kumar for reading early drafts of this post and providing feedback.
-
If you have a better recommendations, please send me an email. ↩
-
If you have many images that you are constantly resizing and compression, I recommend using imgix to do that work on the fly. ↩